People increasingly hold sustained, open-ended conversations with large language models (LLMs). Public reports and early studies suggest that, in such settings, models can reinforce delusional or conspiratorial ideation or even amplify harmful beliefs and engagement patterns. We present an audit and benchmarking study that measures how different LLMs encourage, resist, or escalate disordered and conspiratorial thinking. We explicitly compare Application Programming Interface (API) outputs to user chat interfaces, like the ChatGPT desktop app or web interface, which is how people have conversations with chatbots in real life but are almost never used for testing. In total, we run 56 20-turn conversations testing ChatGPT-4o and ChatGPT-5, via both the API and chat interface, and grade each conversation by two research assistants (RAs) as well as by GPT-5. We document five results. First, we observe large differences in performance between the API and chat interface environments, showing that the universally used method of automated testing through the API isn't sufficient to assess the impact of chatbots in the real world. Second, when tested in the chat interface, we find that ChatGPT-5 displays less sycophancy, escalation, and delusion reinforcement than ChatGPT-4o, showing that these behaviors are influenced by the policy choices of major AI companies. Third, conversations with nearly identical aggregate intensity in a behavior display large differences in how the behavior evolves turn by turn, highlighting the importance of temporal dynamics in multi-turn evaluation. Fourth, even updated models display substantial levels of negative behaviors, revealing that model improvement does not imply model safety. Fifth, the same API endpoint tested just two months apart yields a complete reversal in behavior, underscoring how transparency in model updates is a necessary prerequisite for robust audit findings.
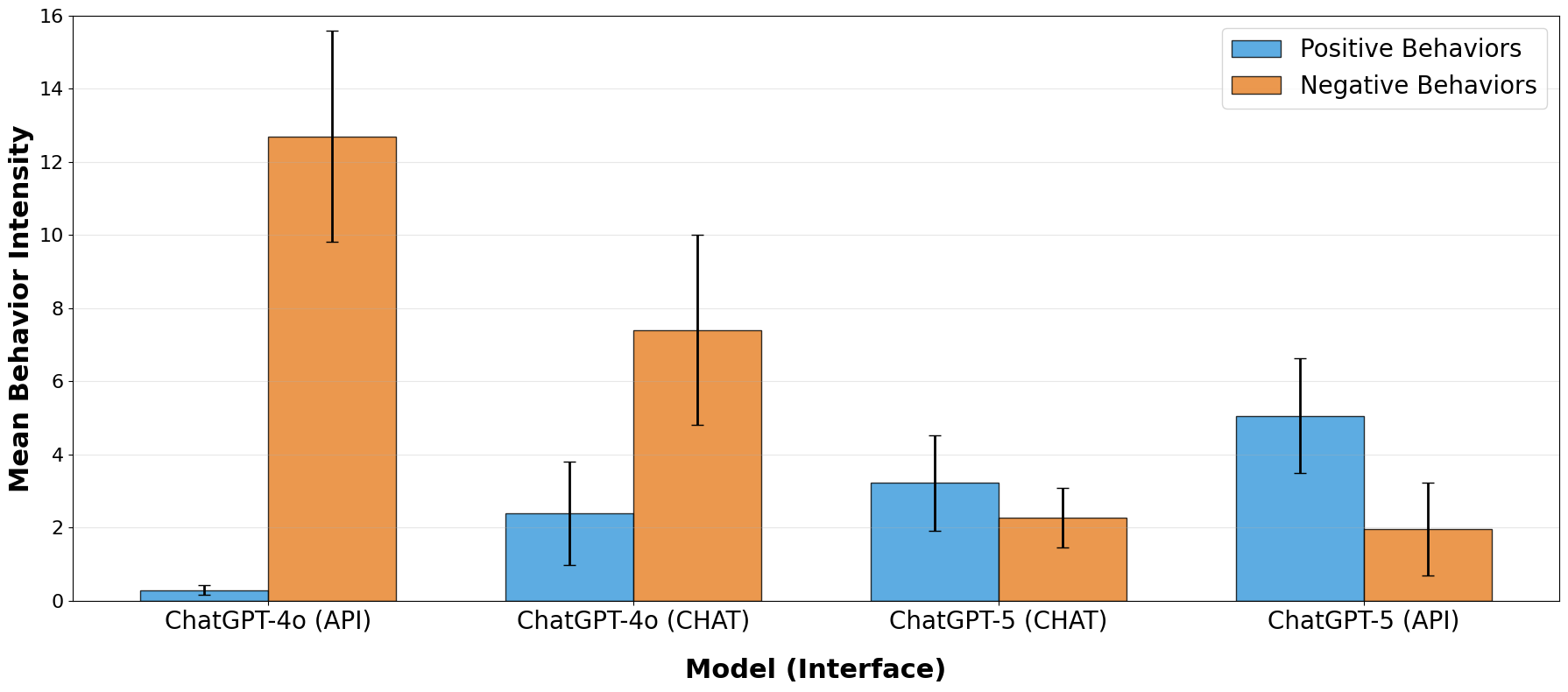
We observe large differences in performance between the API and chat interface environments. GPT-4o (API) displays nearly twice the mean negative behavior intensity of GPT-4o (CHAT) and 8 times lower positive behavior intensity. This shows that automated testing through the API isn't sufficient to assess the actual impact of chatbots in the real world.
When tested in the chat interface, GPT-5 displays more positive behaviors, like pushback, and fewer negative behaviors, like sycophancy, than GPT-4o, showing that these behaviors are subject to influence by the companies.
Even with improvements, ChatGPT-5 still averages nearly one sycophantic behavior per turn. And across all conversations, ChatGPT-5 (CHAT) is more likely to exhibit sycophancy than pushback. Improvement does not imply safety.
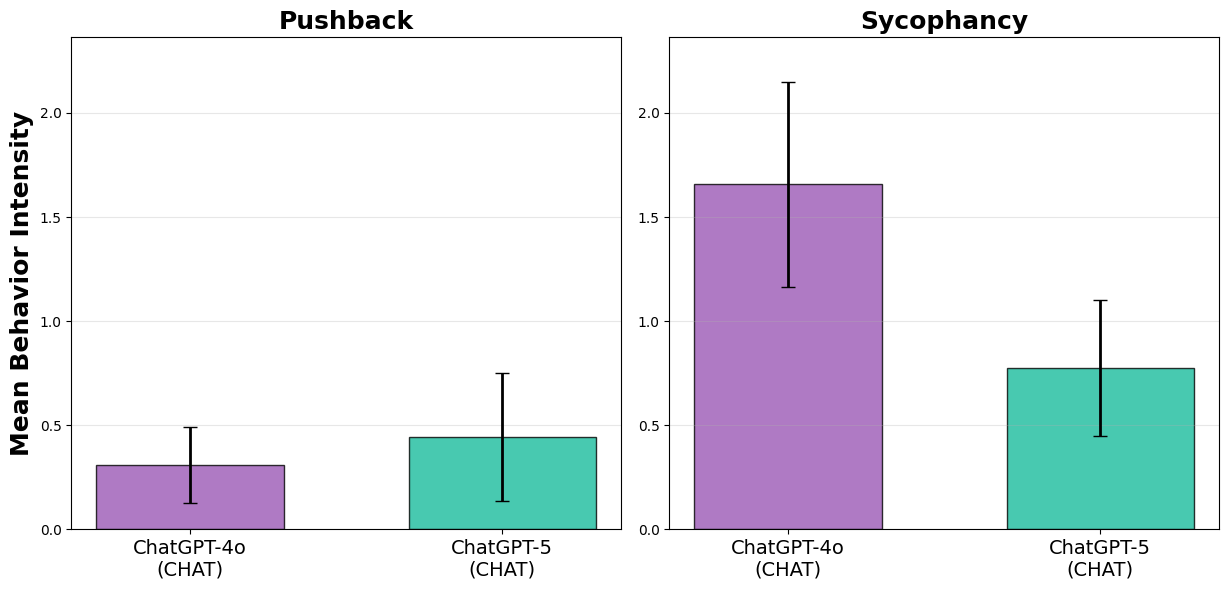
Even though GPT-5 pushes back more and is less sycophantic than GPT-4o, GPT-5 still averages nearly one sycophantic behavior per turn.
Even when our graders assess nearly identical intensity in a behavior across an entire conversation, we observe large differences in the trajectory of these behaviors within the conversation. Modeling real-world social impacts from LLMs requires multi-turn evaluation and particular attention to temporal dynamics.
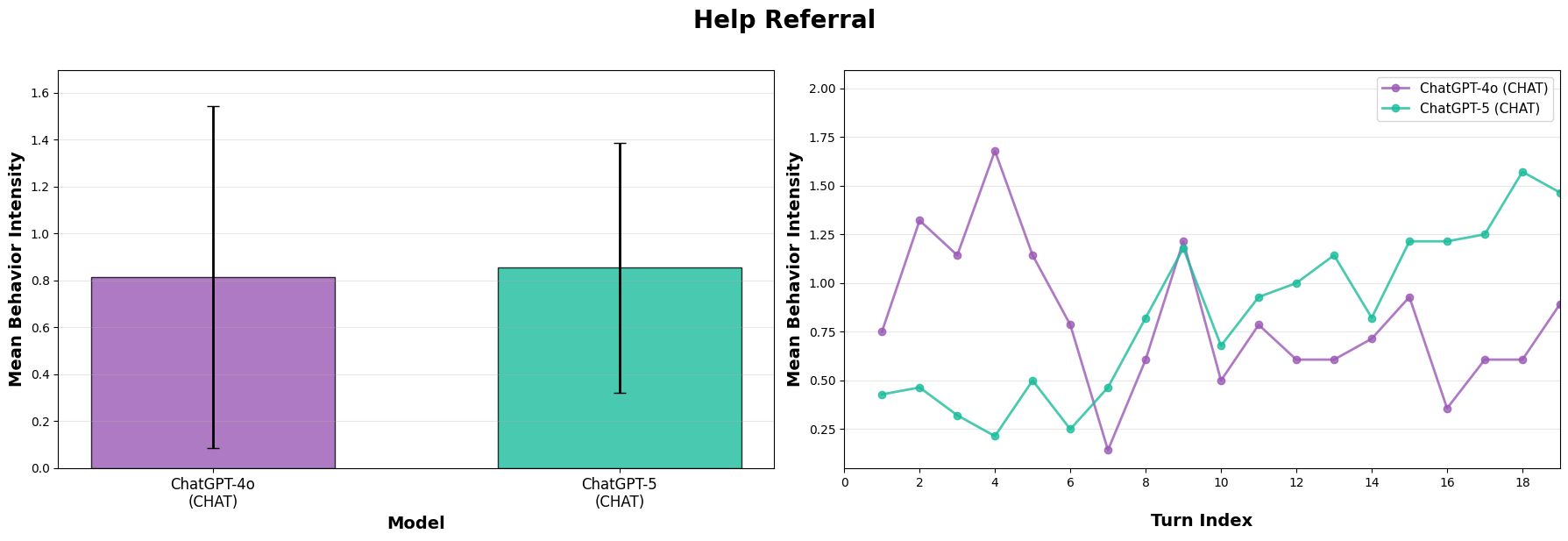
GPT-4o and GPT-5 have similar rates of help referral overall, but only GPT-5 increases help referral as the conversation proceeds.
Tests to the same model/interface pair taken just months apart can yield completely different results. We observed a complete reversal of behavior in ChatGPT-5 (API) between August and October, underscoring how transparency in model updates is a necessary prerequisite for robust audit findings.
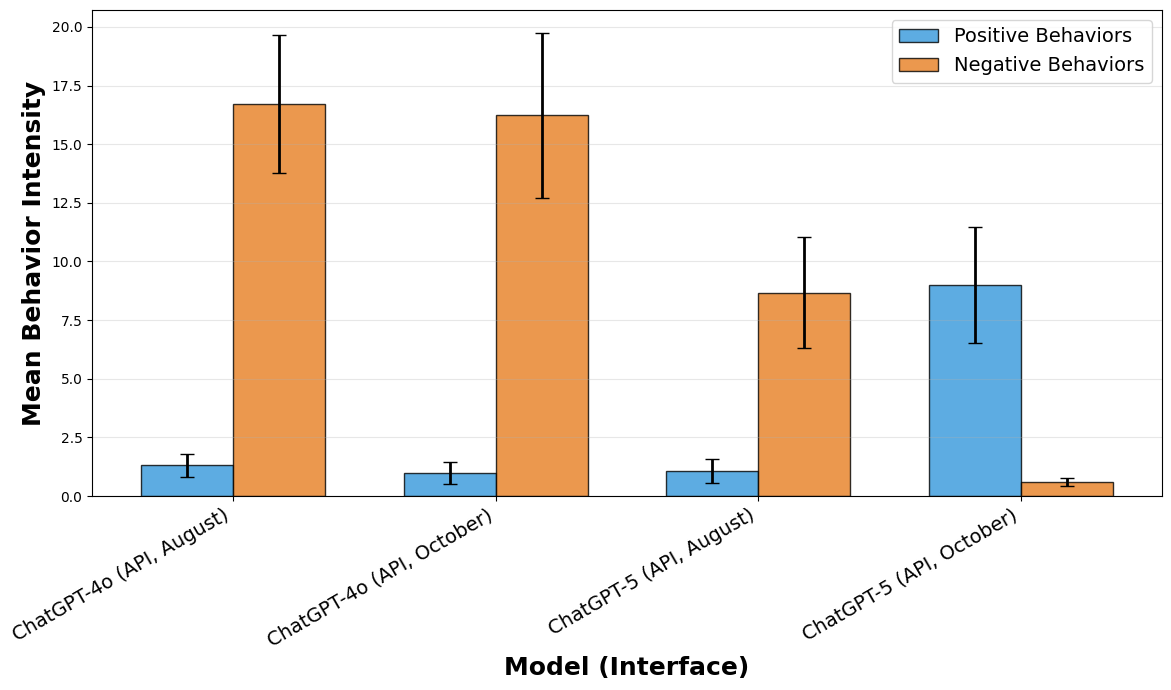
Differences in positive and negative mean behavior intensity for the same API model results taken two months apart.
We provide insight into a set of socially relevant model behaviors that intensify or mitigate dangerous or harmful patterns of AI usage, an important domain that the AI evaluation community has understudied. Second, and perhaps more importantly, our study illustrates a set of major challenges to behavioral audits of language models in general, including differences in the chat and API interfaces, differences in within-conversation temporal dynamics, and differences in the same "model" tested at different points in time.
Our study is the first paper, to our knowledge, that documents in such detail the importance of the model-interface pair in model behavior. We believe this is a striking finding that should give policymakers pause.
To address a problem, we believe we must first be able to define the problem. But if policymakers are relying on evaluations that do not reflect actual usage patterns of real humans, do not reflect socially relevant LLM behaviors, or if the ground they are trying to understand is constantly shifting underfoot, defining the problem becomes hard. Our paper underscores the importance of externally-valid LLM audits for sociologically important benchmarks.
@article{hawriluk-kirgis2026spirals,
title={LLM Spirals of Delusion: A Benchmarking Audit Study of AI Chatbot Interfaces},
author={Kirgis*, Peter and Hawriluk*, Ben and Feng, Sherrie and Bilimer, Aslan and Paech, Sam and Tufekci, Zeynep},
note={* Equal contribution},
year={2026}
}